Getting Started with KerasNLP
Author: Jonathan Bischof
Date created: 2022/12/15
Last modified: 2023/07/01
Description: An introduction to the KerasNLP API.

Introduction
KerasNLP is a natural language processing library that supports users through their entire development cycle. Our workflows are built from modular components that have state-of-the-art preset weights and architectures when used out-of-the-box and are easily customizable when more control is needed.
This library is an extension of the core Keras API; all high-level modules are
Layers or Models. If you are familiar with Keras,
congratulations! You already understand most of KerasNLP.
KerasNLP uses Keras 3 to work with any of TensorFlow, Pytorch and Jax. In the
guide below, we will use the jax backend for training our models, and
tf.data for efficiently running our
input preprocessing. But feel free to mix things up! This guide runs in
TensorFlow or PyTorch backends with zero changes, simply update the
KERAS_BACKEND below.
This guide demonstrates our modular approach using a sentiment analysis example at six levels of complexity:
- Inference with a pretrained classifier
- Fine tuning a pretrained backbone
- Fine tuning with user-controlled preprocessing
- Fine tuning a custom model
- Pretraining a backbone model
- Build and train your own transformer from scratch
Throughout our guide, we use Professor Keras, the official Keras mascot, as a visual reference for the complexity of the material:
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # Upgrade to Keras 3.
import os
os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
import keras_nlp
import keras
# Use mixed precision to speed up all training in this guide.
keras.mixed_precision.set_global_policy("mixed_float16")
API quickstart
Our highest level API is keras_nlp.models. These symbols cover the complete user
journey of converting strings to tokens, tokens to dense features, and dense features to
task-specific output. For each XX architecture (e.g., Bert), we offer the following
modules:
- Tokenizer:
keras_nlp.models.XXTokenizer- What it does: Converts strings to sequences of token ids.
- Why it's important: The raw bytes of a string are too high dimensional to be useful
features so we first map them to a small number of tokens, for example
"The quick brown fox"to["the", "qu", "##ick", "br", "##own", "fox"]. - Inherits from:
keras.layers.Layer.
- Preprocessor:
keras_nlp.models.XXPreprocessor- What it does: Converts strings to a dictionary of preprocessed tensors consumed by the backbone, starting with tokenization.
- Why it's important: Each model uses special tokens and extra tensors to understand the input such as delimiting input segments and identifying padding tokens. Padding each sequence to the same length improves computational efficiency.
- Has a:
XXTokenizer. - Inherits from:
keras.layers.Layer.
- Backbone:
keras_nlp.models.XXBackbone- What it does: Converts preprocessed tensors to dense features. Does not handle strings; call the preprocessor first.
- Why it's important: The backbone distills the input tokens into dense features that can be used in downstream tasks. It is generally pretrained on a language modeling task using massive amounts of unlabeled data. Transferring this information to a new task is a major breakthrough in modern NLP.
- Inherits from:
keras.Model.
- Task: e.g.,
keras_nlp.models.XXClassifier- What it does: Converts strings to task-specific output (e.g., classification probabilities).
- Why it's important: Task models combine string preprocessing and the backbone model
with task-specific
Layersto solve a problem such as sentence classification, token classification, or text generation. The additionalLayersmust be fine-tuned on labeled data. - Has a:
XXBackboneandXXPreprocessor. - Inherits from:
keras.Model.
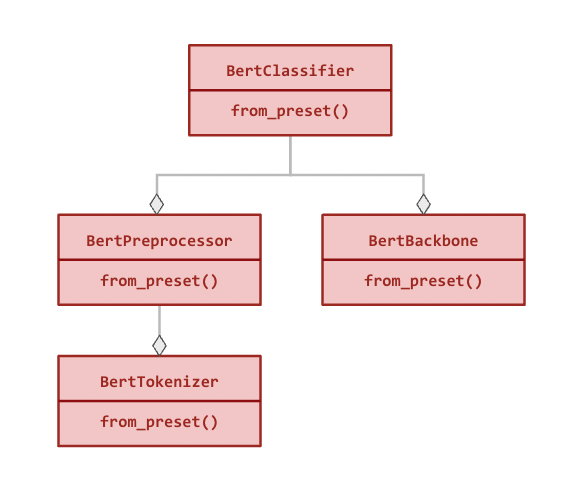
Here is the modular hierarchy for BertClassifier (all relationships are compositional):
All modules can be used independently and have a from_preset() method in addition to
the standard constructor that instantiates the class with preset architecture and
weights (see examples below).
Data
We will use a running example of sentiment analysis of IMDB movie reviews. In this task,
we use the text to predict whether the review was positive (label = 1) or negative
(label = 0).
We load the data using keras.utils.text_dataset_from_directory, which utilizes the
powerful tf.data.Dataset format for examples.
!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
!# Remove unsupervised examples
!rm -r aclImdb/train/unsup
BATCH_SIZE = 16
imdb_train = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
)
imdb_test = keras.utils.text_dataset_from_directory(
"aclImdb/test",
batch_size=BATCH_SIZE,
)
# Inspect first review
# Format is (review text tensor, label tensor)
print(imdb_train.unbatch().take(1).get_single_element())
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 80.2M 100 80.2M 0 0 88.0M 0 --:--:-- --:--:-- --:--:-- 87.9M
Found 25000 files belonging to 2 classes.
Found 25000 files belonging to 2 classes.
(<tf.Tensor: shape=(), dtype=string, numpy=b'This is a very, very early Bugs Bunny cartoon. As a result, the character is still in a transition period--he is not drawn as elongated as he later was and his voice isn\'t quite right. In addition, the chemistry between Elmer and Bugs is a little unusual. Elmer is some poor sap who buys Bugs from a pet shop--there is no gun or desire on his part to blast the bunny to smithereens! However, despite this, this is still a very enjoyable film. The early Bugs was definitely more sassy and cruel than his later incarnations. In later films, he messed with Elmer, Yosimite Sam and others because they started it--they messed with the rabbit. But, in this film, he is much more like Daffy Duck of the late 30s and early 40s--a jerk who just loves irritating others!! A true "anarchist" instead of the hero of the later cartoons. While this isn\'t among the best Bug Bunny cartoons, it sure is fun to watch and it\'s interesting to see just how much he\'s changed over the years.'>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
Inference with a pretrained classifier

The highest level module in KerasNLP is a task. A task is a keras.Model
consisting of a (generally pretrained) backbone model and task-specific layers.
Here's an example using keras_nlp.models.BertClassifier.
Note: Outputs are the logits per class (e.g., [0, 0] is 50% chance of positive). The output is
[negative, positive] for binary classification.
classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
# Note: batched inputs expected so must wrap string in iterable
classifier.predict(["I love modular workflows in keras-nlp!"])
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 689ms/step
array([[-1.539, 1.543]], dtype=float16)
All tasks have a from_preset method that constructs a keras.Model instance with
preset preprocessing, architecture and weights. This means that we can pass raw strings
in any format accepted by a keras.Model and get output specific to our task.
This particular preset is a "bert_tiny_uncased_en" backbone fine-tuned on
sst2, another movie review sentiment analysis (this time from Rotten Tomatoes). We use
the tiny architecture for demo purposes, but larger models are recommended for SoTA
performance. For all the task-specific presets available for BertClassifier, see
our keras.io models page.
Let's evaluate our classifier on the IMDB dataset. You will note we don't need to
call keras.Model.compile here. All task models like BertClassifier ship with
compilation defaults, meaning we can just call keras.Model.evaluate directly. You
can always call compile as normal to override these defaults (e.g. to add new metrics).
The output below is [loss, accuracy],
classifier.evaluate(imdb_test)
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 4s 2ms/step - loss: 0.4610 - sparse_categorical_accuracy: 0.7882
[0.4630218744277954, 0.783519983291626]
Our result is 78% accuracy without training anything. Not bad!
Fine tuning a pretrained BERT backbone

When labeled text specific to our task is available, fine-tuning a custom classifier can improve performance. If we want to predict IMDB review sentiment, using IMDB data should perform better than Rotten Tomatoes data! And for many tasks, no relevant pretrained model will be available (e.g., categorizing customer reviews).
The workflow for fine-tuning is almost identical to above, except that we request a
preset for the backbone-only model rather than the entire classifier. When passed
a backbone preset, a task Model will randomly initialize all task-specific
layers in preparation for training. For all the backbone presets available for
BertClassifier, see our keras.io models page.
To train your classifier, use keras.Model.fit as with any other
keras.Model. As with our inference example, we can rely on the compilation
defaults for the task and skip keras.Model.compile. As preprocessing is
included, we again pass the raw data.
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased",
num_classes=2,
)
classifier.fit(
imdb_train,
validation_data=imdb_test,
epochs=1,
)
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 16s 9ms/step - loss: 0.5202 - sparse_categorical_accuracy: 0.7281 - val_loss: 0.3254 - val_sparse_categorical_accuracy: 0.8621
<keras.src.callbacks.history.History at 0x7f281ffc9f90>
Here we see a significant lift in validation accuracy (0.78 -> 0.87) with a single epoch of
training even though the IMDB dataset is much smaller than sst2.
Fine tuning with user-controlled preprocessing

For some advanced training scenarios, users might prefer direct control over
preprocessing. For large datasets, examples can be preprocessed in advance and saved to
disk or preprocessed by a separate worker pool using tf.data.experimental.service. In
other cases, custom preprocessing is needed to handle the inputs.
Pass preprocessor=None to the constructor of a task Model to skip automatic
preprocessing or pass a custom BertPreprocessor instead.
Separate preprocessing from the same preset
Each model architecture has a parallel preprocessor Layer with its own
from_preset constructor. Using the same preset for this Layer will return the
matching preprocessor as the task.
In this workflow we train the model over three epochs using tf.data.Dataset.cache(),
which computes the preprocessing once and caches the result before fitting begins.
Note: we can use tf.data for preprocessing while running on the
Jax or PyTorch backend. The input dataset will automatically be converted to
backend native tensor types during fit. In fact, given the efficiency of tf.data
for running preprocessing, this is good practice on all backends.
import tensorflow as tf
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=512,
)
# Apply the preprocessor to every sample of train and test data using `map()`.
# [`tf.data.AUTOTUNE`](https://www.tensorflow.org/api_docs/python/tf/data/AUTOTUNE) and `prefetch()` are options to tune performance, see
# https://www.tensorflow.org/guide/data_performance for details.
# Note: only call `cache()` if you training data fits in CPU memory!
imdb_train_cached = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_cached = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased", preprocessor=None, num_classes=2
)
classifier.fit(
imdb_train_cached,
validation_data=imdb_test_cached,
epochs=3,
)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 15s 8ms/step - loss: 0.5194 - sparse_categorical_accuracy: 0.7272 - val_loss: 0.3032 - val_sparse_categorical_accuracy: 0.8728
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2871 - sparse_categorical_accuracy: 0.8805 - val_loss: 0.2809 - val_sparse_categorical_accuracy: 0.8818
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 7ms/step - loss: 0.2134 - sparse_categorical_accuracy: 0.9178 - val_loss: 0.3043 - val_sparse_categorical_accuracy: 0.8790
<keras.src.callbacks.history.History at 0x7f281ffc87f0>
After three epochs, our validation accuracy has only increased to 0.88. This is both a
function of the small size of our dataset and our model. To exceed 90% accuracy, try
larger presets such as "bert_base_en_uncased". For all the backbone presets
available for BertClassifier, see our keras.io models page.
Custom preprocessing
In cases where custom preprocessing is required, we offer direct access to the
Tokenizer class that maps raw strings to tokens. It also has a from_preset()
constructor to get the vocabulary matching pretraining.
Note: BertTokenizer does not pad sequences by default, so the output is
ragged (each sequence has varying length). The MultiSegmentPacker below
handles padding these ragged sequences to dense tensor types (e.g. tf.Tensor
or torch.Tensor).
tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
# Write your own packer or use one of our `Layers`
packer = keras_nlp.layers.MultiSegmentPacker(
start_value=tokenizer.cls_token_id,
end_value=tokenizer.sep_token_id,
# Note: This cannot be longer than the preset's `sequence_length`, and there
# is no check for a custom preprocessor!
sequence_length=64,
)
# This function that takes a text sample `x` and its
# corresponding label `y` as input and converts the
# text into a format suitable for input into a BERT model.
def preprocessor(x, y):
token_ids, segment_ids = packer(tokenizer(x))
x = {
"token_ids": token_ids,
"segment_ids": segment_ids,
"padding_mask": token_ids != 0,
}
return x, y
imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
# Preprocessed example
print(imdb_train_preprocessed.unbatch().take(1).get_single_element())
({'token_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 101, 2023, 2003, 2941, 2028, 1997, 2026, 5440, 3152,
1010, 1045, 2052, 16755, 2008, 3071, 12197, 2009, 1012,
2045, 2003, 2070, 2307, 3772, 1999, 2009, 1998, 2009,
3065, 2008, 2025, 2035, 1000, 2204, 1000, 3152, 2024,
2137, 1012, 1012, 1012, 1012, 102, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(64,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False])>}, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
Fine tuning with a custom model
For more advanced applications, an appropriate task Model may not be available. In
this case, we provide direct access to the backbone Model, which has its own
from_preset constructor and can be composed with custom Layers. Detailed examples can
be found at our transfer learning guide.
A backbone Model does not include automatic preprocessing but can be paired with a
matching preprocessor using the same preset as shown in the previous workflow.
In this workflow, we experiment with freezing our backbone model and adding two trainable transformer layers to adapt to the new input.
Note: We can ignore the warning about gradients for the pooled_dense layer because
we are using BERT's sequence output.
preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
imdb_train_preprocessed = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_preprocessed = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
backbone.trainable = False
inputs = backbone.input
sequence = backbone(inputs)["sequence_output"]
for _ in range(2):
sequence = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=512,
dropout=0.1,
)(sequence)
# Use [CLS] token output to classify
outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
model = keras.Model(inputs, outputs)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.summary()
model.fit(
imdb_train_preprocessed,
validation_data=imdb_test_preprocessed,
epochs=3,
)
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ segment_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ bert_backbone_3 │ [(None, 128), │ 4,385,… │ padding_mask[0][0], │ │ (BertBackbone) │ (None, None, │ │ segment_ids[0][0], │ │ │ 128)] │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encoder │ (None, None, 128) │ 198,272 │ bert_backbone_3[0][… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ get_item_4 │ (None, 128) │ 0 │ transformer_encoder… │ │ (GetItem) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dense (Dense) │ (None, 2) │ 258 │ get_item_4[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
Total params: 4,782,722 (18.24 MB)
Trainable params: 396,802 (1.51 MB)
Non-trainable params: 4,385,920 (16.73 MB)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 17s 10ms/step - loss: 0.6208 - sparse_categorical_accuracy: 0.6612 - val_loss: 0.6119 - val_sparse_categorical_accuracy: 0.6758
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.5324 - sparse_categorical_accuracy: 0.7347 - val_loss: 0.5484 - val_sparse_categorical_accuracy: 0.7320
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 12s 8ms/step - loss: 0.4735 - sparse_categorical_accuracy: 0.7723 - val_loss: 0.4874 - val_sparse_categorical_accuracy: 0.7742
<keras.src.callbacks.history.History at 0x7f2790170220>
This model achieves reasonable accuracy despite having only 10% of the trainable parameters
of our BertClassifier model. Each training step takes about 1/3 of the time—even
accounting for cached preprocessing.
Pretraining a backbone model

Do you have access to large unlabeled datasets in your domain? Are they around the same size as used to train popular backbones such as BERT, RoBERTa, or GPT2 (XX+ GiB)? If so, you might benefit from domain-specific pretraining of your own backbone models.
NLP models are generally pretrained on a language modeling task, predicting masked words
given the visible words in an input sentence. For example, given the input
"The fox [MASK] over the [MASK] dog", the model might be asked to predict ["jumped", "lazy"].
The lower layers of this model are then packaged as a backbone to be combined with
layers relating to a new task.
The KerasNLP library offers SoTA backbones and tokenizers to be trained from scratch without presets.
In this workflow, we pretrain a BERT backbone using our IMDB review text. We skip the "next sentence prediction" (NSP) loss because it adds significant complexity to the data processing and was dropped by later models like RoBERTa. See our e2e Transformer pretraining for step-by-step details on how to replicate the original paper.
Preprocessing
# All BERT `en` models have the same vocabulary, so reuse preprocessor from
# "bert_tiny_en_uncased"
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=256,
)
packer = preprocessor.packer
tokenizer = preprocessor.tokenizer
# keras.Layer to replace some input tokens with the "[MASK]" token
masker = keras_nlp.layers.MaskedLMMaskGenerator(
vocabulary_size=tokenizer.vocabulary_size(),
mask_selection_rate=0.25,
mask_selection_length=64,
mask_token_id=tokenizer.token_to_id("[MASK]"),
unselectable_token_ids=[
tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
],
)
def preprocess(inputs, label):
inputs = preprocessor(inputs)
masked_inputs = masker(inputs["token_ids"])
# Split the masking layer outputs into a (features, labels, and weights)
# tuple that we can use with keras.Model.fit().
features = {
"token_ids": masked_inputs["token_ids"],
"segment_ids": inputs["segment_ids"],
"padding_mask": inputs["padding_mask"],
"mask_positions": masked_inputs["mask_positions"],
}
labels = masked_inputs["mask_ids"]
weights = masked_inputs["mask_weights"]
return features, labels, weights
pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
pretrain_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
# Tokens with ID 103 are "masked"
print(pretrain_ds.unbatch().take(1).get_single_element())
({'token_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([ 101, 103, 2332, 103, 1006, 103, 103, 2332, 2370,
1007, 103, 2029, 103, 2402, 2155, 1010, 24159, 2000,
3541, 7081, 1010, 2424, 2041, 2055, 1996, 9004, 4528,
103, 103, 2037, 2188, 103, 1996, 2269, 1006, 8512,
3054, 103, 4246, 1007, 2059, 4858, 1555, 2055, 1996,
23025, 22911, 8940, 2598, 3458, 1996, 25483, 4528, 2008,
2038, 103, 1997, 15218, 1011, 103, 1997, 103, 2505,
3950, 2045, 3310, 2067, 2025, 3243, 2157, 1012, 103,
7987, 1013, 1028, 103, 7987, 1013, 1028, 2917, 103,
1000, 5469, 1000, 103, 103, 2041, 22902, 1010, 23979,
1010, 1998, 1999, 23606, 103, 1998, 4247, 2008, 2126,
2005, 1037, 2096, 1010, 2007, 1996, 103, 5409, 103,
2108, 3054, 3211, 4246, 1005, 1055, 22692, 2836, 1012,
2009, 103, 1037, 2210, 2488, 103, 103, 2203, 1010,
2007, 103, 103, 9599, 1012, 103, 2391, 1997, 2755,
1010, 1996, 2878, 3185, 2003, 2428, 103, 1010, 103,
103, 103, 1045, 2064, 1005, 1056, 3294, 19776, 2009,
1011, 2012, 2560, 2009, 2038, 2242, 2000, 103, 2009,
13432, 1012, 11519, 4637, 4616, 2011, 5965, 1043, 11761,
103, 103, 2004, 103, 7968, 3243, 4793, 11429, 1010,
1998, 8226, 2665, 18331, 1010, 1219, 1996, 4487, 22747,
8004, 12165, 4382, 5125, 103, 3597, 103, 2024, 2025,
2438, 2000, 103, 2417, 21564, 2143, 103, 103, 7987,
1013, 1028, 1026, 103, 1013, 1028, 2332, 2038, 103,
5156, 12081, 2004, 1996, 103, 1012, 1026, 14216, 103,
103, 1026, 7987, 1013, 1028, 184, 2011, 1037, 8297,
2036, 103, 2011, 2984, 103, 1006, 2003, 2009, 2151,
4687, 2008, 2016, 1005, 1055, 2018, 2053, 7731, 103,
103, 2144, 1029, 102], dtype=int32)>, 'segment_ids': <tf.Tensor: shape=(256,), dtype=int32, numpy=
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)>, 'padding_mask': <tf.Tensor: shape=(256,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True])>, 'mask_positions': <tf.Tensor: shape=(64,), dtype=int64, numpy=
array([ 1, 3, 5, 6, 10, 12, 13, 27, 28, 31, 37, 42, 51,
55, 59, 61, 65, 71, 75, 80, 83, 84, 85, 94, 105, 107,
108, 118, 122, 123, 127, 128, 131, 141, 143, 144, 145, 149, 160,
167, 170, 171, 172, 174, 176, 185, 193, 195, 200, 204, 205, 208,
210, 215, 220, 223, 224, 225, 230, 231, 235, 238, 251, 252])>}, <tf.Tensor: shape=(64,), dtype=int32, numpy=
array([ 4459, 6789, 22892, 2011, 1999, 1037, 2402, 2485, 2000,
1012, 3211, 2041, 9004, 4204, 2069, 2607, 3310, 1026,
1026, 2779, 1000, 3861, 4627, 1010, 7619, 5783, 2108,
4152, 2646, 1996, 15958, 14888, 1999, 14888, 2029, 2003,
2339, 1056, 2191, 2011, 11761, 2638, 1010, 1996, 2214,
2004, 14674, 2860, 2428, 1012, 1026, 1028, 7987, 2010,
2704, 7987, 1013, 1028, 2628, 2011, 2856, 12838, 2143,
2147], dtype=int32)>, <tf.Tensor: shape=(64,), dtype=float16, numpy=
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], dtype=float16)>)
Pretraining model
# BERT backbone
backbone = keras_nlp.models.BertBackbone(
vocabulary_size=tokenizer.vocabulary_size(),
num_layers=2,
num_heads=2,
hidden_dim=128,
intermediate_dim=512,
)
# Language modeling head
mlm_head = keras_nlp.layers.MaskedLMHead(
token_embedding=backbone.token_embedding,
)
inputs = {
"token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
"segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
"padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
"mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
}
# Encoded token sequence
sequence = backbone(inputs)["sequence_output"]
# Predict an output word for each masked input token.
# We use the input token embedding to project from our encoded vectors to
# vocabulary logits, which has been shown to improve training efficiency.
outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
# Define and compile our pretraining model.
pretraining_model = keras.Model(inputs, outputs)
pretraining_model.summary()
pretraining_model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
# Pretrain on IMDB dataset
pretraining_model.fit(
pretrain_ds,
validation_data=pretrain_val_ds,
epochs=3, # Increase to 6 for higher accuracy
)
Model: "functional_3"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ mask_positions │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ segment_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ bert_backbone_4 │ [(None, 128), │ 4,385,… │ mask_positions[0][0… │ │ (BertBackbone) │ (None, None, │ │ padding_mask[0][0], │ │ │ 128)] │ │ segment_ids[0][0], │ │ │ │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ masked_lm_head │ (None, None, │ 3,954,… │ bert_backbone_4[0][… │ │ (MaskedLMHead) │ 30522) │ │ mask_positions[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘
Total params: 4,433,210 (16.91 MB)
Trainable params: 4,433,210 (16.91 MB)
Non-trainable params: 0 (0.00 B)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 22s 12ms/step - loss: 5.7032 - sparse_categorical_accuracy: 0.0566 - val_loss: 5.0685 - val_sparse_categorical_accuracy: 0.1044
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 5.0701 - sparse_categorical_accuracy: 0.1096 - val_loss: 4.9363 - val_sparse_categorical_accuracy: 0.1239
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 13s 8ms/step - loss: 4.9607 - sparse_categorical_accuracy: 0.1240 - val_loss: 4.7913 - val_sparse_categorical_accuracy: 0.1417
<keras.src.callbacks.history.History at 0x7f2738299330>
After pretraining save your backbone submodel to use in a new task!
Build and train your own transformer from scratch
Want to implement a novel transformer architecture? The KerasNLP library offers all the
low-level modules used to build SoTA architectures in our models API. This includes the
keras_nlp.tokenizers API which allows you to train your own subword tokenizer using
WordPieceTokenizer, BytePairTokenizer, or SentencePieceTokenizer.
In this workflow, we train a custom tokenizer on the IMDB data and design a backbone with custom transformer architecture. For simplicity, we then train directly on the classification task. Interested in more details? We wrote an entire guide to pretraining and finetuning a custom transformer on keras.io,
Train custom vocabulary from IMDB data
vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
imdb_train.map(lambda x, y: x),
vocabulary_size=20_000,
lowercase=True,
strip_accents=True,
reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
)
tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
vocabulary=vocab,
lowercase=True,
strip_accents=True,
oov_token="[UNK]",
)
Preprocess data with a custom tokenizer
packer = keras_nlp.layers.StartEndPacker(
start_value=tokenizer.token_to_id("[START]"),
end_value=tokenizer.token_to_id("[END]"),
pad_value=tokenizer.token_to_id("[PAD]"),
sequence_length=512,
)
def preprocess(x, y):
token_ids = packer(tokenizer(x))
return token_ids, y
imdb_preproc_train_ds = imdb_train.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
imdb_preproc_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
(<tf.Tensor: shape=(512,), dtype=int32, numpy=
array([ 1, 102, 11, 61, 43, 771, 16, 340, 916,
1259, 155, 16, 135, 207, 18, 501, 10568, 344,
16, 51, 206, 612, 211, 232, 43, 1094, 17,
215, 155, 103, 238, 202, 18, 111, 16, 51,
143, 1583, 131, 100, 18, 32, 101, 19, 34,
32, 101, 19, 34, 102, 11, 61, 43, 155,
105, 5337, 99, 120, 6, 1289, 6, 129, 96,
526, 18, 111, 16, 193, 51, 197, 102, 16,
51, 252, 11, 62, 167, 104, 642, 98, 6,
8572, 6, 154, 51, 153, 1464, 119, 3005, 990,
2393, 18, 102, 11, 61, 233, 404, 103, 104,
110, 18, 18, 18, 233, 1259, 18, 18, 18,
154, 51, 659, 16273, 867, 192, 1632, 133, 990,
2393, 18, 32, 101, 19, 34, 32, 101, 19,
34, 96, 110, 2886, 761, 114, 4905, 293, 12337,
97, 2375, 18, 113, 143, 158, 179, 104, 4905,
610, 16, 12585, 97, 516, 725, 18, 113, 323,
96, 651, 146, 104, 207, 17649, 16, 96, 176,
16022, 136, 16, 1414, 136, 18, 113, 323, 96,
2184, 18, 97, 150, 651, 51, 242, 104, 100,
11722, 18, 113, 151, 543, 102, 171, 115, 1081,
103, 96, 222, 18, 18, 18, 18, 102, 659,
1081, 18, 18, 18, 102, 11, 61, 115, 299,
18, 113, 323, 96, 1579, 98, 203, 4438, 2033,
103, 96, 222, 18, 18, 18, 32, 101, 19,
34, 32, 101, 19, 34, 111, 16, 51, 455,
174, 99, 859, 43, 1687, 3330, 99, 104, 1021,
18, 18, 18, 51, 181, 11, 62, 214, 138,
96, 155, 100, 115, 916, 14, 1286, 14, 99,
296, 96, 642, 105, 224, 4598, 117, 1289, 156,
103, 904, 16, 111, 115, 103, 1628, 18, 113,
181, 11, 62, 119, 96, 1054, 155, 16, 111,
156, 14665, 18, 146, 110, 139, 742, 16, 96,
4905, 293, 12337, 97, 7042, 1104, 106, 557, 103,
366, 18, 128, 16, 150, 2446, 135, 96, 960,
98, 96, 4905, 18, 113, 323, 156, 43, 1174,
293, 188, 18, 18, 18, 43, 639, 293, 96,
455, 108, 207, 97, 1893, 99, 1081, 104, 4905,
18, 51, 194, 104, 440, 98, 12337, 99, 7042,
1104, 654, 122, 30, 6, 51, 276, 99, 663,
18, 18, 18, 97, 138, 113, 207, 163, 16,
113, 171, 172, 107, 51, 1027, 113, 6, 18,
32, 101, 19, 34, 32, 101, 19, 34, 104,
110, 171, 333, 10311, 141, 1311, 135, 140, 100,
207, 97, 140, 100, 99, 120, 1632, 18, 18,
18, 97, 210, 11, 61, 96, 6236, 293, 188,
18, 51, 181, 11, 62, 214, 138, 96, 421,
98, 104, 110, 100, 6, 207, 14129, 122, 18,
18, 18, 151, 1128, 97, 1632, 1675, 6, 133,
6, 207, 100, 404, 18, 18, 18, 150, 646,
179, 133, 210, 6, 18, 111, 103, 152, 744,
16, 104, 110, 100, 557, 43, 1120, 108, 96,
701, 382, 105, 102, 260, 113, 194, 18, 18,
18, 2, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
Design a tiny transformer
token_id_input = keras.Input(
shape=(None,),
dtype="int32",
name="token_ids",
)
outputs = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=len(vocab),
sequence_length=packer.sequence_length,
embedding_dim=64,
)(token_id_input)
outputs = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=128,
dropout=0.1,
)(outputs)
# Use "[START]" token to classify
outputs = keras.layers.Dense(2)(outputs[:, 0, :])
model = keras.Model(
inputs=token_id_input,
outputs=outputs,
)
model.summary()
Model: "functional_5"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ token_ids (InputLayer) │ (None, None) │ 0 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ token_and_position_embedding │ (None, None, 64) │ 1,259,648 │ │ (TokenAndPositionEmbedding) │ │ │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ transformer_encoder_2 │ (None, None, 64) │ 33,472 │ │ (TransformerEncoder) │ │ │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ get_item_6 (GetItem) │ (None, 64) │ 0 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense_1 (Dense) │ (None, 2) │ 130 │ └─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 1,293,250 (4.93 MB)
Trainable params: 1,293,250 (4.93 MB)
Non-trainable params: 0 (0.00 B)
Train the transformer directly on the classification objective
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.fit(
imdb_preproc_train_ds,
validation_data=imdb_preproc_val_ds,
epochs=3,
)
Epoch 1/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/step - loss: 0.7790 - sparse_categorical_accuracy: 0.5367 - val_loss: 0.4420 - val_sparse_categorical_accuracy: 0.8120
Epoch 2/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.3654 - sparse_categorical_accuracy: 0.8443 - val_loss: 0.3046 - val_sparse_categorical_accuracy: 0.8752
Epoch 3/3
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.2471 - sparse_categorical_accuracy: 0.9019 - val_loss: 0.3060 - val_sparse_categorical_accuracy: 0.8748
<keras.src.callbacks.history.History at 0x7f26d032a4d0>
Excitingly, our custom classifier is similar to the performance of fine-tuning
"bert_tiny_en_uncased"! To see the advantages of pretraining and exceed 90% accuracy we
would need to use larger presets such as "bert_base_en_uncased".